Во многих организациях есть внутренние проекты, которыми занимается программисты ИТ-отдела. Такие проекты часто скатываются в говно (как программное обеспечение), ибо релизить не надо, все пользователи под боком, на проблемы апгрейда-миграции пофиг — весьма распространённое мнение, между прочим. Намерения у программистов может и благие, но результат почти всегда плачевен: обязательно настанет время, когда прибить новый костыль к программе окажется некуда.
Совсем печально становится, когда такой проект достаётся «в наследство» от предыдущих поколений программистов. Многие программисты считают, что такой проект — это карьерный тупик, поэтому найти квалифицированного разработчика на легаси (=legacy) проект часто очень сложно — они воспринимают такую работу как нечто вроде ИТ-ассенизатора. В чём-то они правы, однако не всё так плохо, поскольку такая работа предоставляет редкий шанс проявить себя в роли «решателя проблем» — весьма полезный навык, пригодится в будущем, если решите пойти по менеджерской лестнице.
Часто внутренний проект — это вебсайт для решения внутренних задач организаци: учёт, общение, клиенты и т.п. Сайт этот работает с незапамятных времён, к нему привыкли, его «пилит» уже не одно поколение программистов. Периодически функциональность сайта расширяются, достраиваются новые этажи, прибиваются новые костыли и приклеиваются подпорки; однако с каждым днём поддерживать его становится всё сложнее и сложнее, и уже на горизонте проступает надвигающийся кризис развития проекта (а другие сопутствующие проблемы, как правило, уже прямо тут зверствуют).
Источник проблем¶
Говнокод неизбежен, весь вопрос только в его количестве и качестве. Нельзя пускать на самотёк развитие системы, делая упор только на собственно код и игнорируя все «второстепенные» задачи интеграционного/инфраструктурного характера.
Ну то есть говнокод — это такое комплексное понятие, не только программный код, но и всякие другие проблемы:
- Отсутствие актуальной проектной документации. И тут ещё непонятно, что хуже: устаревшая документация или её отсутствие, поскольку часто устаревшая документация не позволяет узнать, в какой момент развития системы она собственно устарела.
- Код — говно, объективно говно. Тут два направления: дерьмово оформленный и дерьмово написанный код; первое часто влечёт второе. Качественно оформленный код значительно ускоряет время на его анализ.
- Отдельный вариант предыдущего пункта — это код-только-на-боевом-сервере; это когда единственная работающая версия проекта крутится на сайте и на неё боятся чихнуть, чтобы ничего не отвалилось.
- Как попало выстроенная архитектура, когда непонятно, что откуда следуети и что от чего зависит. Это в некотором роде объединение первых двух пунктов списка.
- Нет инфраструктуры сопровождения проекта (тестов, сценариев развёртывания/тестирования, репозитория кода и других сходных инструментов).
Говнокод на то и говнокод, что его нельзя быстро поправить, нельзя резко и быстро решить перечисленные выше проблемы. Но можно решить постепенно, плавно подводя систему к нормально поддерживаемому состоянию.
Оптимальная стратегия избавления от говнокода зависит от общей цели и направления развития проекта, это исключительно важный момент, поскольку в одних обстоятельствах может оказаться, что проще проект просто выкинуть и написать с нуля; а в других — что ничего вообще нельзя сделать и придётся только молиться, чтобы ничего не обвалилось в работающей системе. В жизни обычно нечто среднее.
Очень важно осознать, что целью работы является не написание крутого кода, а эффективное решение поставленных задач при помощи проекта. То есть придётся активно вникать в бизнес-процессы, общаться с пользователями и начальством, чтобы потом реализовать в проекте их требования.
Исходная ситуация и начало работы¶
В самом начале перед стартом работ по легаси-проекту нужно организовать и подготовить место, где будет постепенно накапливаться информация по нему, постепенно превращаясь в проектную документацию. Это должно быть что-то простое и легко масштабируемое, например, wiki.
Если в фирме уже есть вики, заводим в ней отдельный раздел для нашего проекта. Если вики нет, то создаём (у отдела наверняка есть выделенный сервер для собственных целей). Пока работающего wiki-сайта нет, лучше дальше даже не читать, поскольку наша вики будет ядром всей работы над разгребанием проекта. Более детально о работе с вики поговорим в отдельном разделе, а сейчас нам пока хватит одной стартовой страницы и страниц, создаваемых по мере необходимости и перечисленных в виде ссылок на главной странице. Часть информации можно попробовать уложить в виде mind maps, если вы знаете, что это, и умеете с ними работать. Или в других диаграммах.
Итак, первый шаг — это исследование и анализ унаследованного проекта, все результаты описываем в одном документе:
- Какая документация существует для проекта, её актуальность. Всё найденное свести на одной странице, чтобы можно было сразу перейти на нужный документ. Для каждого документа указать область применения и степень актуальности.
- Оценить важность и востребованность системы и её компонентов по отдельности. Коротко описать, для чего вообще предназначена система, какие задачи должна решать и какие решает в реальности.
- Кто был из текущих сотрудников ранее вовлечён в разработку проекта. Кто из уже неработающих сотрудников. Указать, кто в какое время и чем занимался. Всё это позволит в будущем в случае каких-то проблем обратиться к этим людям за помощью.
- Какие серверы вовлечены в проект, роль каждого сервераю Например, веб-сервер, СУБД, хранилище файлов и т.п. Координаты, адреса серверов, контакты ответственных персон.
- Кто вообще пользуется системой, роли этих персон, координаты, как активно пользуются. Построить иерархию заказчиков фич по важности их приоритета. Перечислить конкретных людей или группы людей, пользующихся системой, попытаться примерно оценить, насколько система важна для этих персон или групп, как много ей пользуются.
По мере работы над проектом нужно смело менять структуру проектной документации в вики (например, переименовывать/перемещать документы), чтобы таким итерационным путём прийти к наиболее эффективной структуре. Пишите коротко, но понятно, по максимуму лаконично и понятно. Пошаговые инструкции рулят, пишите их много и подробно, самим потом пригодится не раз. Инструкции должны быть максимально подробными, чтобы любой человек со стороны мог по ним выполнить действия, по минимуму отвлекая разработчиков.
Первостепенные проблемы и решения¶
Нет репозитория с кодом¶
У внутренних проектов есть одна характерная именно для них проблема — слабое окружение (environment). То есть нет строгого контроля за исходным кодом, всё отдаётся на усмотрение разработчиков, которые «пилят» продукт как им удобно в текущий момент. Самым крайним случаем является правка кода прямо на работающем сервере и вообще отсутствие второй копии кода кроме той, которая на работающем сервере.
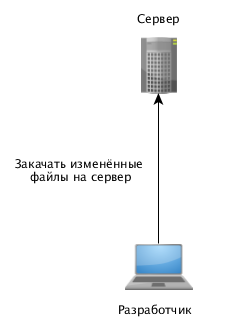 Самая простая ситуация: систему разрабатывает один программист, периодически закачивает обновлённый код на сервер. Поскольку сервер обновляет один человек, такая схема может долго и успешно работать. Но только до появления ещё одного разработчика.
Самая простая ситуация: систему разрабатывает один программист, периодически закачивает обновлённый код на сервер. Поскольку сервер обновляет один человек, такая схема может долго и успешно работать. Но только до появления ещё одного разработчика.
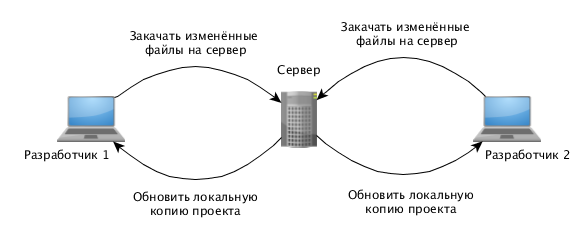
А вот что получается, когда систему разрабатывают два программиста. Каждому из разработчиков приходится периодически вручную скачивать код с сервера и обновлять локальную копию. Такой подход обязательно приведёт к бардаку и потере кода, причём теряться код может безвозвратно. Координировать такой процесс разработки очень сложно и на практике — особенно при активной правке кода — что-нибудь обязательно ломается.
Эту схему в обязательном порядке ломаем, не может быть никаких оправданий для её дальнейшего существования. Ломать, естественно, нужно очень аккуратно. Вот примерный план, как можно организовать работу над кодом внутреннего проекта, объяснения сразу после картинки.
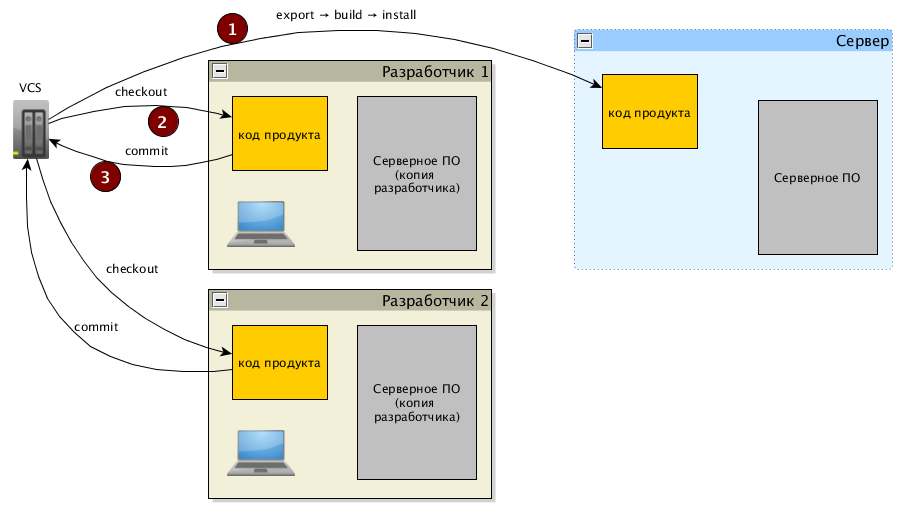
Программное обеспечение на сервере можно условно разделить на две части: подконтрольную (собственно код продукта, например) и стороннее ПО (веб-сервер, операционная система, СУБД и т.п.) Код проекта (т.е. подконтрольный код) должен храниться в репозитории (SVN, git и т.п.), а на боевой сервер попадать только через чётко описанный процесс развёртывания (помечено на схеме цифрой 1), причём из репозитория, а не из локальных копий разработчиков (которые работают с репозиторием стандартными методами, помеченными 2 и 3). Такой подход позволит ликвидировать конфликты кода, поскольку всё хранится в репозитории и конфликты разруливаются уже накатанными методами. Схема развёртывания обязана храниться в проектной документации, это должна быть подробная пошаговая инструкция, предельно точная и детальная; очень круто будет, если часть шагов будет автоматизирована скриптами (как минимум сборку можно автоматизировать).
В вики пишем инструкцию по работе с репозиторием: как делать checkout, commit, пути к репозиториям, другие полезные данные.
Стороннее ПО (на схеме помечено как «Серверное ПО») можно хранить отдельно, но обязательно нужна инструкция по его развёртыванию в боевой, тестовый или девелоперский экземпляр. Инструкцию — в проектную документацию.
Бардак с СУБД¶
В проекте наверняка используется какая-то СУБД (mysql, например), порядка в ней никакого нет, скорее всего. Поэтому дальше обязательно анализируем структуру СУБД и организуем бэкап базы данных.
Анализ структуры СУБД сводится к рисованию концептуальной схемы СУБД: с квадратиками, стрелочками, метками и подсказками; для рисования можно взять, например, Dia или yEd. Исходный файл схемы коммитим в репозиторий с кодом, а экспортную картинку — в нашу вики-документацию. Схему периодически придётся обновлять, не забываем экспортить каждый раз в картинку в вики.
Схема базы исключительно важна, а особенно полезна для быстрого погружения в проект новых сотрудников.
Бэкап должен выполняться регулярно программой-планировщиком в автоматическом релизе. Обязательно убедитесь, что итоговый бэкап действительно можно восстановить в работающую систему. Все подробности работы бэкапных программ и инструкцию по восстановлению традиционно записываем в вики.
Туманная архитектура¶
Сразу восстановить архитектуру проекта у вас не получится, но на каком-то уровне вполне можно, хотя бы на уровне пользовательского интерфейса. Всё обнаруженное в понятном и чётком виде традиционно записываем в вики.
Можно рисовать всякие диаграммы, если это поможет пониманию. Исходные файлы диаграмм также записываем в репозиторий, а экспортнутые картинки — в вики.
Не стоит кидаться сразу всё исправлять на «правильный вариант», сначала изучите систему как можно подробнее. Её ведь до вас не дураки писали, нужно найти побольше граблей в проекте, чтобы самому на них не наступать.
Код низкого качества¶
Просто так сесть и переписать всё правильно не получится, как бы вам этого ни хотелось — даже не начинайте. Вместо этого начинайте аккуратно распутывать код по мере необходимости.
Например, понадобилось добавить новую фичу в файл report.php. До вас эту фичу добавили бы очень просто: открыли файл в редакторы и по-быстрому наговнякали очередной костыль. Естественно, это неправильно.
Главное правило работы с говнокодом: Говнокод должен уменьшаться после работы с ним. Это значит, что когда вы открываете файл для изменения, старайтесь исправлять в нём что-нибудь: оформление кода (приводите его к какому-нибудь стандарту, чтобы стал более читабельным), меняйте названия локальных переменных на более понятные (но аккуратнее не с локальными переменными), оставляйте много понятных и разумных комментариев в коде (выяснили, зачем нужен метод — написали рядом), удаляйте бессмысленные и неконструктивные комментарии. Помните, что качественно оформленный код читается гораздо легче.
Никакого рефакторинга, поскольку у вас нет тестов для кода, вносите сложные изменения, только если чётко понимаете, что делаете.
Бардак с фичами и процессами¶
Наверняка кто-то периодически хочет добавить в проект новую фичу. С этого момента никаких устных просьб, всё исключительно в письменном виде через email. А лучше завести трекер (если его раньше не было) для подобного общения, всё должно идти только через него, даже общение между разработчиками.
Организуйте процесс рассмотрения новых фич, оповестите о нём всех причастных персон. Следуйте только этому процессу при реализации новых фич. Баги, естественно, также должны проходить через трекер.
Эффективная работа с вики-системой¶
Если за вики не следить, она тоже превратится в помойку, поэтому нужно за сайтом постоянно следить, наблюдать за оформлением добавляемых документов, наказывать за неконструктивные и невнятные документые, периодически удалять (или скрывать с глаз) устаревшие документы.
Помните, эффективная вики-система — это такая система, которой реально пользуются. Если что-то не устраивает в документе, исправьте или поручите кому-нибудь исправить. Слишком много занудства при работе с вики много не бывает. Но никакого занудства в документах.
Долой канцелярит! Пишите простым и понятным языком. Не жалейте абзацев. Пишите короткими и простыми предложениями, без языковых извращений. Инструкции пишите в виде пошаговых списков.
В начале каждого документа выделите область с коротким описанием содержимого документа.
Если вики-программа позволяет, разбивайте документы на отдельные части. Ссылки — это круто, используйте их повсеместно.
Резюме¶
Рекомендации из этой статьи не превратят говнопроект в конфетку, однако реально упростят вам жизнь, избавят от монотонных рутиных проблем — решать сложные задачи гораздо менее утомительно, чем решать тупые и нудные.
Постоянно следите за документацией, перечитывайте, актуализируйте. Устаревшие документы переводите в какой-нибудь отдельный раздел или как-нибудь помечайте, чтобы они смущали взор и мысли.
Агитируйте других участников проекта писать документацию.
Нет пределов совершенству.
Литература¶
Что полезно почитать по этой и подобным темам.
- Michael Feathers, Working Effectively with Legacy Code
- 97 Things Every Programmer Should Know: Collective Wisdom from the Experts или на русском 97 этюдов для программистов
- Robert C. Martin, The Clean Coder: A Code of Conduct for Professional Programmers
По поводу распутывания кода - лучше всего, наверно, начать с выкидывания мёртвого кода, то есть такого, который никогда не выполняется, или связанного с спрятанным до лучших времён элементом пользовательского интерфейса (такое часто бывает, пока что не нужен - вот и спрятали, жалко код выкинуть, так как про контроль версий не в курсе). Затем попытаться разбить говнокод на более мелкие и логически более правильные модули. После этого править будет легче.
Ещё могу посоветовать нарисовать простой парсер исходников, который генерирует в формате graphviz связи между модулями или функциями в пределах модуля - очень помогает искать ненормальности в коде, вроде циклических зависимостей между модулями, мёртвых (неиспользуемых) кусков кода и прочее.
Спасибо за комментарий, я согласен, в принципе. Разве что такой детальный подход уже тема отдельной статьи или даже книги. Впрочем, книга на такую тематику уже есть — Working Effectively with Legacy Code, в ней как раз рассматриваются вопросы именно кода (со всех сторон, включая, тестирование, анализ и т.п.). А я старался подойти к теме со стороны менеджера проекта, стратегический подход с небольшими вкраплениями практики.